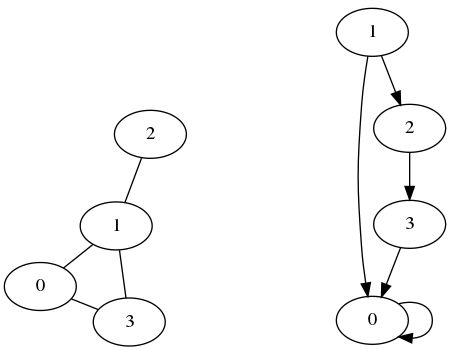
Pour le premier graphe la matrice d'adjacence et le dictionnaire des listes d'adjacence sont:
M1 = [ [0, 1, 0, 1], [1, 0, 1, 1], [0, 1, 0, 0], [1, 1, 0, 0] ]
d1 = { 0: [1, 3], 1: [0, 2, 3], 2: [1], 3: [0, 1] }
Pour le second graphe:
M2 = [ [1, 0, 0, 0], [1, 0, 1, 0], [0, 0, 0, 1], [1, 0, 0, 0] ]
d2 = { 0: [0], 1: [0, 2], 2: [3], 3: [0] }
Dans cet exercice on supposera que les sommets du graphe sont les entiers de $0$ à $n-1$.
Q1. Ecrire une fonction DictAd(M:[list])->dict qui prend pour argument la matrice d'adjacence M d'un graphe (orienté ou non) et renvoie le dictionnaire des listes d'adjacence de ce graphe.
Q2. Ecrire une fonction MatAd(d:dict)->[list] qui prend pour argument le dictionnaire des listes d'adjacence d d'un graphe (orienté ou non) et renvoie la matrice d'adjacence de ce graphe.
Q1. On parcourt la matrice ligne par ligne pour construire la liste d'adjacence de chaque sommet.
def DictAd(M):
d = {}
n = len(M) # nombre de sommets
for i in range(n):
d[i] = []
for j in range(n):
if M[i][j] == 1:
d[i].append(j)
return d
On teste:
def test1():
print("Test pour le graphe 1 : ", DictAd(M1) == d1)
print("Test pour le graphe 2 : ", DictAd(M2) == d2)
test1()
Test pour le graphe 1 : True Test pour le graphe 2 : True
Q2. On crée une matrice nulle ${\tt M}$ puis on parcours les valeurs du dictionnaire ${\tt d}$ des listes d'adjacences: ${\tt M[i][j]=1}$ correspond à ${\tt d[i]=j}$.
def MatAd(d):
n = len(d)
M = [ [ 0 for j in range(n) ] for i in range(n) ]
for i in range(n):
for j in d[i]:
M[i][j] = 1
return M
On teste:
def test2():
print("Test pour le graphe 1 : ", MatAd(d1) == M1)
print("Test pour le graphe 2 : ", MatAd(d2) == M2)
test2()
Test pour le graphe 1 : True Test pour le graphe 2 : True
On pourra utiliser le graphe suivant pour tester les fonctions implémentées dans les deux premières questions:
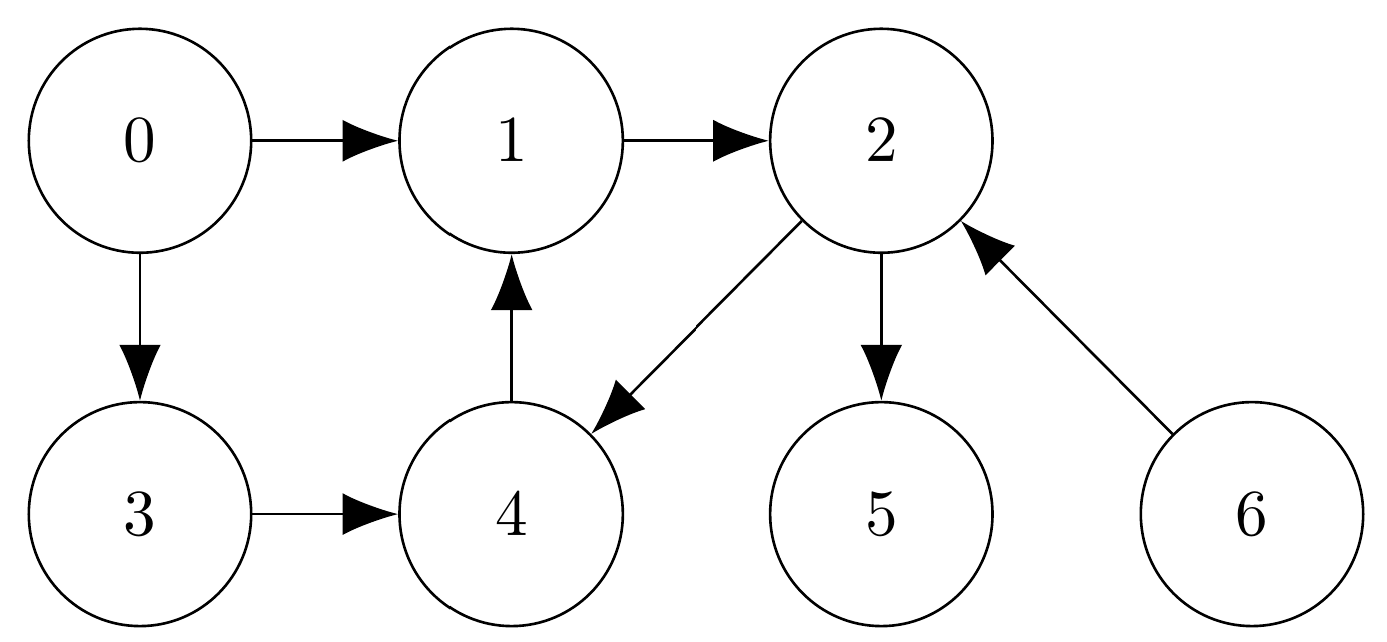
Q1. Ecrire une fonction ParcoursProf(G:list, s:int)->list qui prend en argument G liste d'adjacences d'un graphe et un sommet s de ce graphe et qui renvoie la liste des sommets parcourus lors d'un parcours en profondeur, dans l'ordre où ils ont été parcourus.
Compléter cette fonction pour qu'elle affiche la pile au fur et à mesure de l'exécution et comparer avec la liste des sommets parcourus sur des exemples.
Q2. Même question avec une fonction ParcoursLarg(G:list, s:int)->dict qui réalise un parcours en largeur.
Q3. Ecrire une fonction Comp(G:list, s:int)->list qui prend en argument un graphe non orienté G sous la forme d'une liste d'adjacence et un sommet s et renvoie la composante connexe de s sous la forme d'un dictionnaire d'adjacence.
On pourra tester avec le graphe:
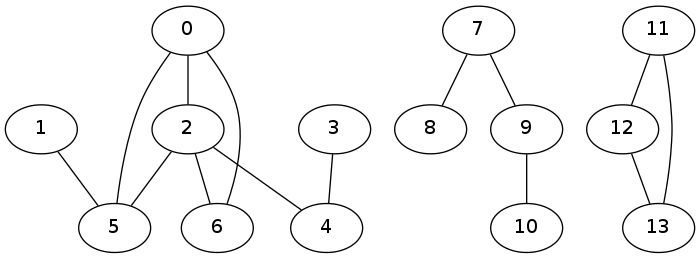
Gcomp = [ [2, 5, 6], [5], [0, 4, 5, 6], [4], [2, 3], [0, 1, 2], [0, 2], [8, 9], [7], [7, 10], [9],
[12, 13], [11, 13], [11, 12] ]
On représente le graphe proposé par une liste d'adjacence:
G = [ [1, 3], [2], [4, 5], [4], [1], [], [2] ]
Q1. On utilise l'algorithme vu en cours. On a signalé en commentaire les lignes ajoutées pour afficher la pile des sommets découverts et construite la liste des sommets parcourus.
def ParcoursProf(G: list , s: int) -> list :
""" Parcours en profondeur du graphe G donné sous forme
d’une liste d’adjacence depuis un sommet s.
Cette fonction renvoie la liste des sommets parcourus dans l'ordre
du parcours"""
visite = [ False for x in G ] # liste des sommets visités
pile = [ s ]
parcours = [] # liste des sommets parcourus
print(pile) # ligne ajoutée
while len(pile) != 0:
x = pile.pop()
print(pile) # ligne ajoutée
if not visite[x]:
visite[x] = True
parcours.append(x) # on ajoute x au parcours
for y in G[x]:
pile.append(y)
print(pile) # ligne ajoutée
return parcours # on renvoie la liste parcours
On teste avec le graphe proposé.
ParcoursProf(G,0)
[0] [] [1] [1, 3] [1] [1, 4] [1] [1, 1] [1] [1, 2] [1] [1, 4] [1, 4, 5] [1, 4] [1] []
[0, 3, 4, 1, 2, 5]
On constate que les sommets visités sont bien ceux qui sont au sommet de la pile.
Q2. On utilise l'algorithme vu en cours. On a signalé en commentaire les lignes ajoutées pour afficher la pile des sommets découverts et construite la liste des sommets parcourus.
import collections
def ParcoursLarg(G: list , s: int) -> list :
""" Parcours en largeur du graphe G donné sous forme
d’une liste d’adjacence depuis un sommet s.
Cette fonction renvoie la liste des sommets parcourus dans l'ordre
du parcours"""
visite = [ False for x in G ] # liste des sommets visités
file = collections.deque()
file.append(s)
parcours = [] # liste des sommets parcourus
print(list(file)) # ligne ajoutée
while len(file) != 0:
x = file.popleft()
print(list(file)) # ligne ajoutée
if not visite[x]:
visite[x] = True
parcours.append(x) # on ajoute x au parcours
for y in G[x]:
file.append(y)
print(list(file)) # ligne ajoutée
return parcours # on renvoie la liste parcours
On teste avec le graphe proposé. On remarque aussi qu'on un sommet peut se trouver plusieurs fois dans la pile avant d'être visité.
ParcoursLarg(G,0)
[0] [] [1] [1, 3] [3] [3, 2] [2] [2, 4] [4] [4, 4] [4, 4, 5] [4, 5] [4, 5, 1] [5, 1] [1] []
[0, 1, 3, 2, 4, 5]
On constate que les sommets visités sont bien ceux qui sont rentrés en premier dans la file. On remarque aussi qu'on un sommet peut se trouver plusieurs fois dans la file avant d'être visité.
Q3. Il suffit de faire un parcours du graphe depuis le sommet désiré. Les sommets parcourus correspondent exactement à la composante connexe recherchée. On choisit le parcours en profondeur.
def Comp(G: list , s: int) -> dict :
""" Calcul de la composante connexe d'un sommet s dans le graphe G donné
sous forme d’un dictionnaire des liste d’adjacences.
Cette fonction renvoie un dictionnaire de listes d'adjacences. """
visite = [ False for x in G ] # liste des sommets visités
pile = [ s ]
composante = {} # composante connexe de s
while len(pile) != 0:
x = pile.pop()
if not visite[x]:
visite[x] = True
composante[x] = [] # liste des voisins de x
for y in G[x]:
pile.append(y)
composante[x].append(y)
return composante # on renvoie la composante connexe
On teste:
def test3():
print("Composante connexe de 0 : ", Comp(Gcomp,0) == { 0: [2, 5, 6], 6: [0, 2], 2: [0, 4, 5, 6], 5: [0, 1, 2], 1: [5], 4: [2, 3], 3: [4] } )
print("Composante connexe de 7 : ", Comp(Gcomp,7) == { 7: [8, 9], 9: [7, 10], 10: [9], 8: [7] } )
print("Composante connexe de 11 : ", Comp(Gcomp,11) == { 11: [12, 13], 13: [11, 12], 12: [11, 13] } )
test3()
Composante connexe de 0 : True Composante connexe de 7 : True Composante connexe de 11 : True
On considère le graphe orienté pondéré suivant:
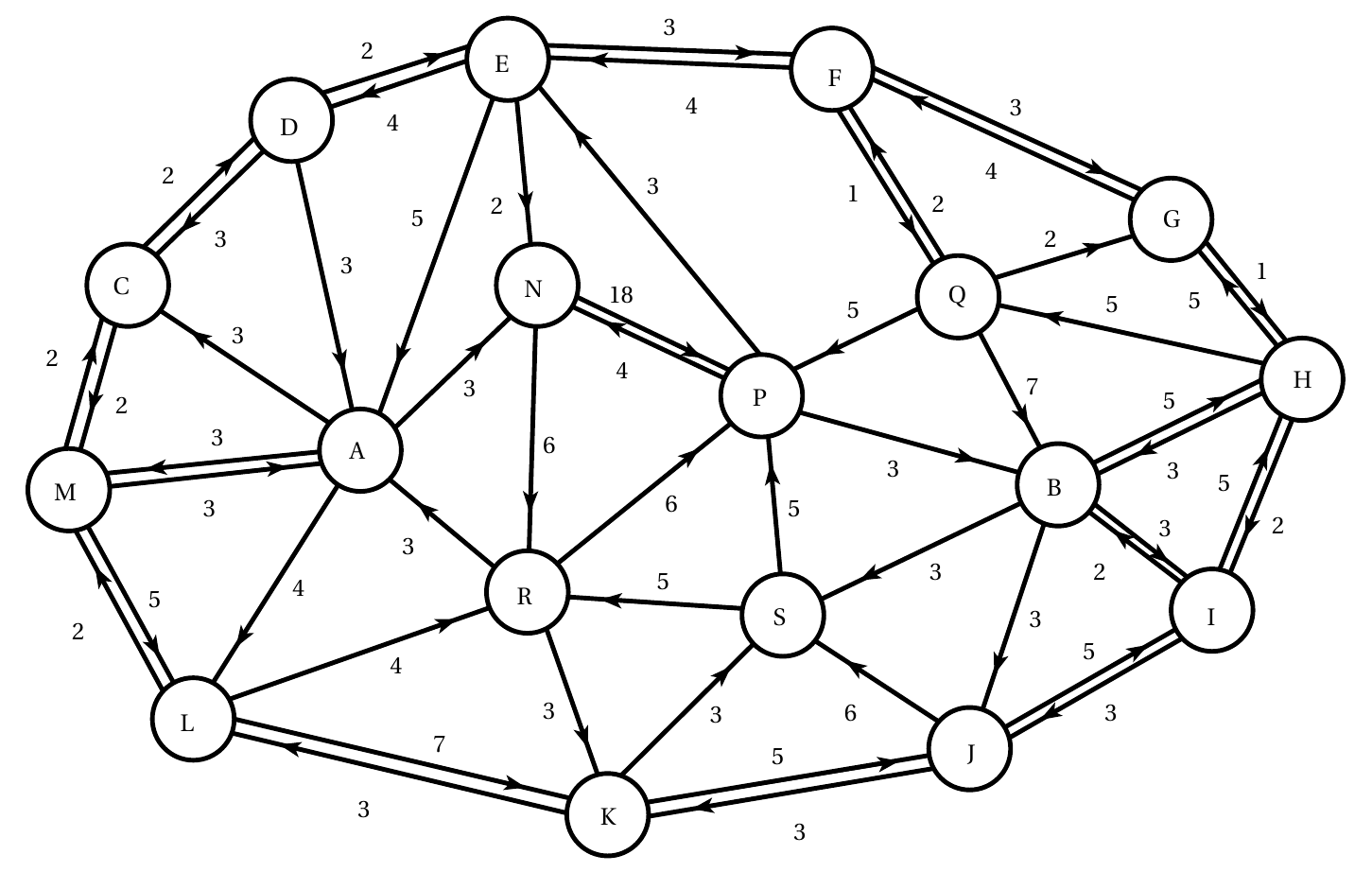
On donne sa représentation sous forme de dictionnaire de listes d'adjacence pondérée:
GG = { 'A': [(3, 'C'), (4, 'L'), (3, 'M'), (3, 'N')],
'B': [(5, 'H'), (3, 'I'), (3, 'J'), (3, 'S')],
'C': [(2, 'D'), (2, 'M')],
'D': [(3, 'A'), (3, 'C'), (2, 'E')],
'E': [(5, 'A'), (4, 'D'), (3, 'F'), (2, 'N')],
'F': [(4, 'E'), (1, 'G'), (1, 'Q')],
'G': [(4, 'F'), (1, 'H')],
'H': [(3, 'B'), (5, 'G'), (2, 'I'), (5, 'Q')],
'I': [(2, 'B'), (5, 'H'), (3, 'J')],
'J': [(5, 'I'), (3, 'K'), (6, 'S')],
'K': [(5, 'J'), (3, 'L'), (3, 'S')],
'L': [(7, 'K'), (2, 'M'), (4, 'R')],
'M': [(3, 'A'), (2, 'C'), (5, 'L')],
'N': [(18, 'P'), (6, 'R')],
'P': [(3, 'B'), (3, 'E'), (4, 'N')],
'Q': [(7, 'B'), (2, 'F'), (2, 'G'), (5, 'P')],
'R': [(3, 'A'), (3, 'K'), (6, 'P')],
'S': [(5, 'P'), (5, 'R')]}
Q1. Ecrire une fonction Dijkstra(G:dict, s:int)->dict qui prend en argument un graphe pondéré sous forme d'un dictionnaire des listes d'adjacences pondérés et renvoie un dictionnaire dont les clés sont les sommets de G et les valeurs la distance du plus court chemin de entre le sommet et s.
Q2. La modifier en une fonction LongPCC(G:dict, s:int, ss:int)->int qui renvoie la longueur du plus court chemin entre s et ss s'il existe et -1 dans le cas contraire.
Q3. La modifier en une fonction PCC(G:dict, s:int, ss:int)->tuple qui renvoie la longueur du plus court chemin entre s et ss et la liste des sommets formant ce plus court chemin.
Pour cela on utilisera un dictionnaire dont les clés sont les sommets du graphe et les valeurs leur prédecesseur dans les plus courts chemins déterminés par l'algorithme.
S'il n'existe pas de chemin entre s et ss cette fonction doit renvoyer (-1, []).
Q1. On utilise l'algorithme vu en cours en l'adaptant à des dictionnaires.
import heapq
def Dijkstra(G: dict , s: int) -> list :
""" Renvoie la liste des plus courtes distances à la source s
calculées avec l'algorithme de Dijkstra pour le graphe de liste d'adjacence␣
, →G."""
visite = { x: False for x in G } # dictionnaire des sommets visités
distance = { x: None for x in G } # dictionnaire des plus courtes distances à la source
file = []
heapq.heappush(file, (0,s))
while len(file) != 0:
p, x = heapq.heappop(file)
if not visite[x]:
visite[x] = True
distance[x] = p
for y in G[x]:
sommet = y[1]
poids = y[0]
heapq.heappush(file,(p+poids, sommet))
return distance # on renvoie la liste des distances
Pour vérifier le résultat:
Dijkstra(GG, 'A') == { 'A': 0.0, 'B': 15.0, 'C': 3.0, 'D': 5.0, 'E': 7.0,
'F': 10.0, 'G': 11.0, 'H': 12.0, 'I': 14.0, 'J': 16.0,
'K': 11.0, 'L': 4.0, 'M': 3.0, 'N': 3.0, 'P': 14.0,
'Q': 11.0, 'R': 8.0, 'S': 14.0 }
True
Q2. On arrête la boucle ${\tt while}$ lorsqu'on visite le sommet qu'on veut atteindre.
def LongPCC(G: dict , s: int, ss:int) -> int :
""" Calcule le plus court chemin entre le sommet s et
le sommets ss dans le graphe G donné sous la
forme d’un dictionnaire de listes d’ adjacence pondérées """
visite = { x: False for x in G } # dictionnaire des sommets visités
distance = { x: None for x in G } # dictionnaire des plus courtes distances à la source
file = []
heapq.heappush(file, (0,s))
while len(file) != 0:
p, x = heapq.heappop(file)
if not visite[x]:
visite[x] = True
distance[x] = p
if x == ss : # si on visite ss
return distance[x] # sortie anticipée de la fonction
for y in G[x]:
sommet = y[1]
poids = y[0]
heapq.heappush(file,(p+poids, sommet))
return -1 # on n'a jamais visité ss (pas dans la bonne composante connexe)
Pour vérifier le résultat:
LongPCC(GG,'A','B') == 15.0
True
Q3. Comme suggéré dans l'énoncé, on utilise un dictionnaire ${\tt predecesseurs}$ dont les clés sont les sommets et les valeurs le prédécesseur de chaque sommet dans le plus court chemin. Celui est calculé lorsqu'on met à jour les distances. Pour trouver le plus court chemin final on doit donc le reconstruire à l'envers en partant du sommet final.
def PCC(G: dict , s: int, ss:int) -> tuple :
""" Calcule la longueur du plus court chemin entre le sommet s et
le sommets ss dans le graphe G donné sous la
forme d’un dictionnaire de listes d’ adjacence pondérées.
Le chemin est aussi renvoyé sous forme d'une liste de sommets. """
visite = { x: False for x in G } # dictionnaire des sommets visités
distance = { x: None for x in G } # dictionnaire des plus courtes distances à la source
predecesseurs = { x: None for x in G } # dictionnaire des prédecesseurs
file = []
heapq.heappush(file, (0, s, None)) # s n'a pas de père
while len(file) != 0:
p, x, pere = heapq.heappop(file)
if not visite[x]:
visite[x] = True
distance[x] = p
predecesseurs[x] = pere
if x == ss : # si on visite ss
chemin = [x]
sommet = x
while sommet != s: # on reconstruit le chemin de s à ss
sommet = predecesseurs[sommet]
chemin = [sommet] + chemin
return (distance[ss], chemin) # sortie anticipée de la fonction
for y in G[x]:
sommet = y[1]
poids = y[0]
heapq.heappush(file,(p+poids, sommet, x)) # x est le père de sommet
return (-1, []) # on n'a jamais visité ss (pas dans la bonne composante connexe)
Pour vérifier le résultat:
PCC(GG, 'A', 'B') == (15.0, ['A', 'C', 'D', 'E', 'F', 'G', 'H', 'B'])
True
On souhaite créer un labyrinthe avec une entrée et une sortie et ensuite trouver le chemin de l'entrée vers la sortie.
Notre labyrinthe va être modélisé par une matrice où les murs seront les cases égales à 0 et les pièces et les passages seront les cases égales à 1.
Par exemple la matrice
lab = [[0, 1, 0, 0, 0, 0, 0, 0, 0],
[0, 1, 1, 1, 0, 1, 1, 1, 0],
[0, 0, 0, 1, 0, 1, 0, 1, 0],
[0, 1, 0, 1, 0, 1, 0, 1, 0],
[0, 1, 0, 1, 0, 0, 0, 1, 0],
[0, 1, 0, 1, 1, 1, 0, 1, 0],
[0, 1, 0, 0, 0, 1, 0, 1, 0],
[0, 1, 1, 1, 1, 1, 1, 1, 0],
[0, 1, 0, 0, 0, 0, 0, 0, 0]]
donne le labyrinthe suivant où l'entrée est en haut à gauche et la sortie en bas à gauche:
import matplotlib.pyplot as plt
plt.imshow(lab)
<matplotlib.image.AxesImage at 0x7f279ba47400>

Un labyrinthe est initialement constitué d'une liste de listes initialement remplie de 0:
$\bullet$ d'un entrée qu'on place aléatoirement sur la première ligne et sur une colonne d'indice impair, la case choisie prenant la valeur 1
$\bullet$ d'une sortie qu'on place aléatoirement sur la dernière ligne et sur une colonne d'indice impair, la case choisie prenant la valeur 1
$\bullet$ de "pièces" qui sont toutes les cases d'indices impairs dans la matrice et, de "passages" qui relient les piéces entre elles, toutes ces cases prenant aussi la valeur 1.
Q1. Ecrire une fonction set_initial_grid(H:int, L:int)->list qui prend en argument deux entiers impairs H et L et renvoie une liste de listes de taille HxL dont toutes les cases valent 0 sauf deux cases qui sont égales à 1 et qui représentent l'entrée et la sortie du labyrinthe comme définies ci-dessus. Cette fonction doit aussi renvoyer le numéro de la colonne où se trouve l'entrée et la sortie.
Pour choisir un entier de manière aléatoire on pourra utiliser la fonction randint du module random.
Pour créer notre labyrinthe on utilise l'algorithme suivant, inspiré de l'algorithme de parcours en profondeur d'un graphe, pour donner à toutes les "pièces" la valeur 1 et choisir aléatoirement les "passages" à qui on donne aussi la valeur 1:
$\bullet$ on se place sur la "pièce" adjacente à notre entrée et on donne la valeur 1 à cette case
$\bullet$ on initialise une pile avec cette "pièce" marquée par la valeur 1
$\bullet$ tant que notre pile n'est pas vide:
$\bullet$ on détermine la liste des "pièces" adjacentes à la "pièce" courante qui n'ont pas encore été marquées par la valeur 1.
$\bullet$ si cette liste n'est pas vide:$\bullet$ on choisit au hasard une de ces "pièces" (on pourra utiliser la fonction ${\tt choice}$ du module ${\tt random}$) et on la marque en lui donnant la valeur 1; on donne aussi la valeur 1 au passage entre cette nouvelle "pièce" marquée et la "pièce" courante.
$\bullet$ la nouvelle "pièce" marquée est empilée dans notre pile et devient la nouvelle "pièce" courante
$\bullet$ si la liste des "pièces" adjacentes non encore marquées est vide, on dépile une "pièce" de notre pile et elle devient la "pièce" courante.
Voici un exemple de construction:
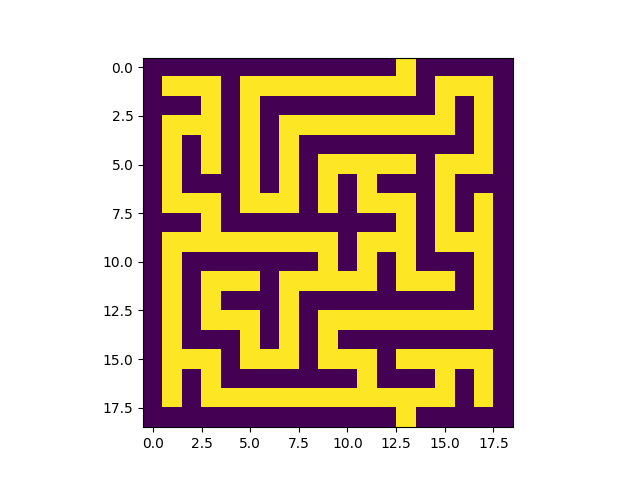 |
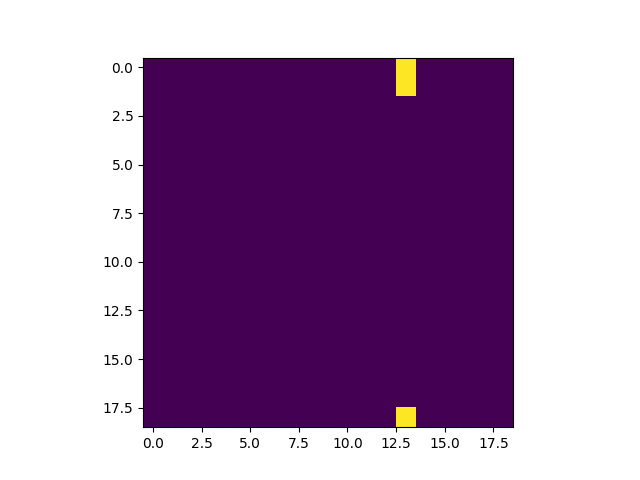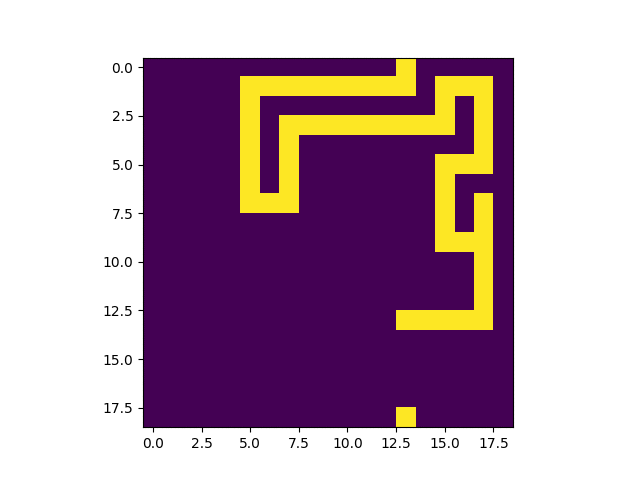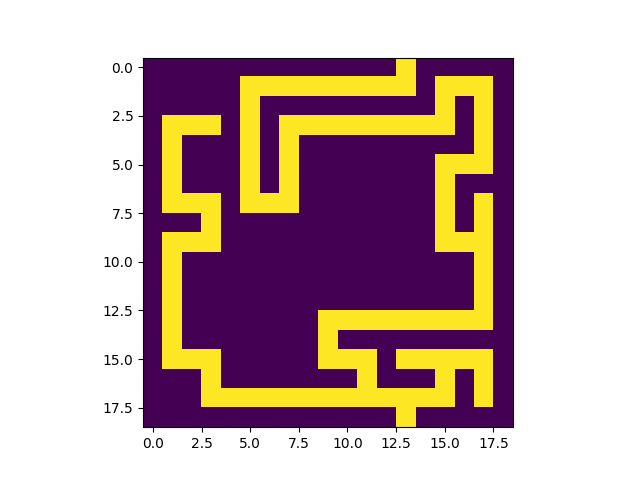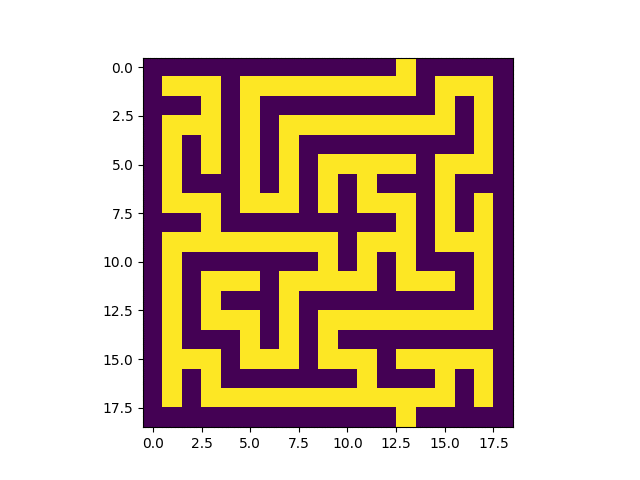 |
Q2. Ecrire une fonction check_voisinage(lab:list, pos:tuple)->list qui prend en argument une liste de listes lab représentant un labyrinthe en cours de création selon l'algorithme ci-dessus et un tuple pos de deux entiers représentant une "pièce" du labyrinthe et renvoie la liste des "pièces" voisines qui n'ont pas encore été visitées par l'algorithme (c'est-à-dire celles qui ont pour valeur 0).
Q3. Ecrire une fonction CreeLab(H:int, L:int)->list qui prend en argument deux entiers impairs H et L et renvoie une liste de listes représentant un labyrinthe de taille HxL créé selon l'algorithme
ci-dessus.
Maintenant qu'on sait créer un labyrinthe on va cherche le chemin entre l'entrée et la sortie. On utlise encore un algorithme inspiré de l'algorithme de parcours en profondeur d'un graphe. Cette fois on va donner la valeur 3 aux "pièces" et aux "passages" qui sont sur le bon chemin et la valeur 2 aux "pièces" et aux "passages" qui ont mené à une impasse.
$\bullet$ on se place sur la "pièce" adjacente à notre entrée et on donne la valeur 3 à cette case ainsi qu'à la case de l'entrée.
$\bullet$ on initialise une pile avec cette "pièce" marquée par la valeur 3
$\bullet$ tant que la "pièce" courante n'est pas la sortie:
$\bullet$ on détermine la liste des "pièces" adjacentes à la "pièce" courante qui n'ont pas encore été explorées c'est-à-dire marquées par les valeurs 2 ou 3.
$\bullet$ si cette liste n'est pas vide:$\bullet$ on choisit au hasard une de ces "pièces" et on la marque en lui donnant la valeur 3; on donne aussi la valeur 3 au passage entre cette nouvelle "pièce" marquée et la "pièce" courante.
$\bullet$ la nouvelle "pièce" marquée est empilée dans notre pile et devient la nouvelle "pièce" courante
$\bullet$ si la liste des "pièces" adjacentes non encore explorées est vide, c'est qu'on est dans une impasse. On marque cette "pièce" et le passage qui nous y a mené avec la valeur 2 puis on dépile deux "pièces" de notre pile (pour revenir d'une étape en arrière). La dernière "pièce" dépilée devient la "pièce" courante.
Voici un exemple de résolution:
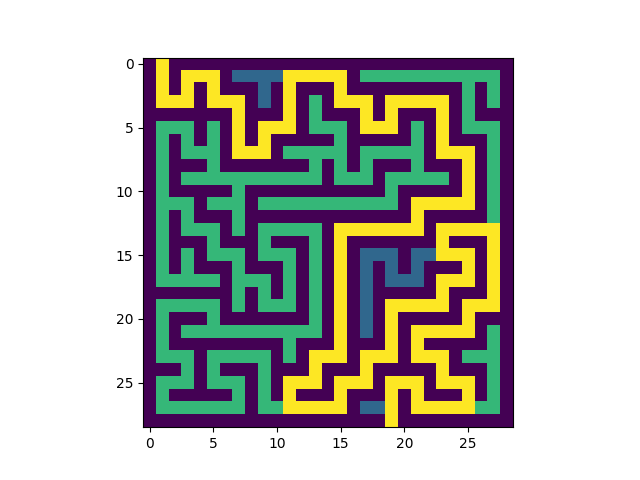 |
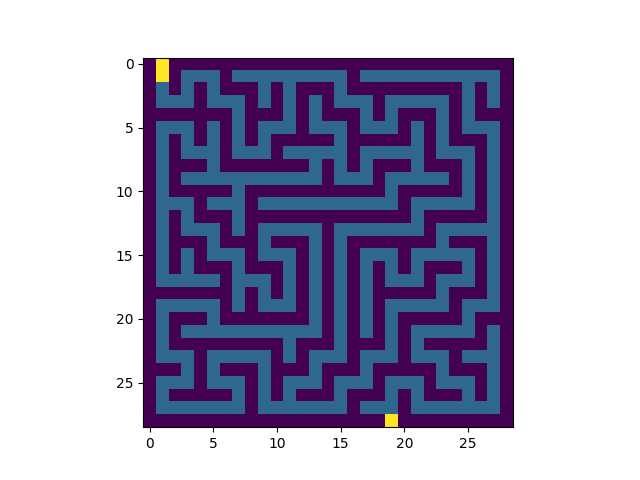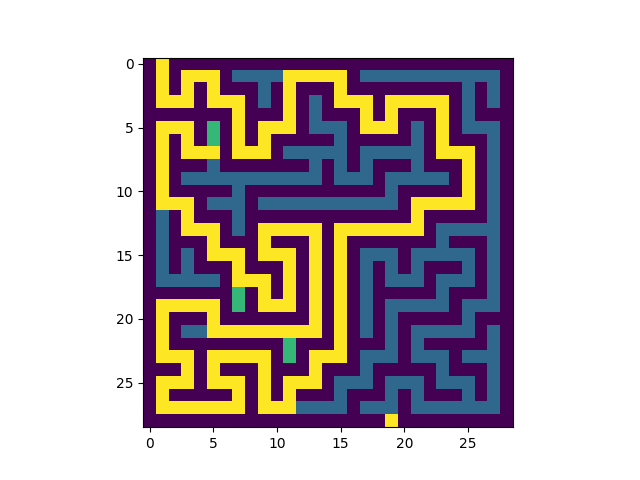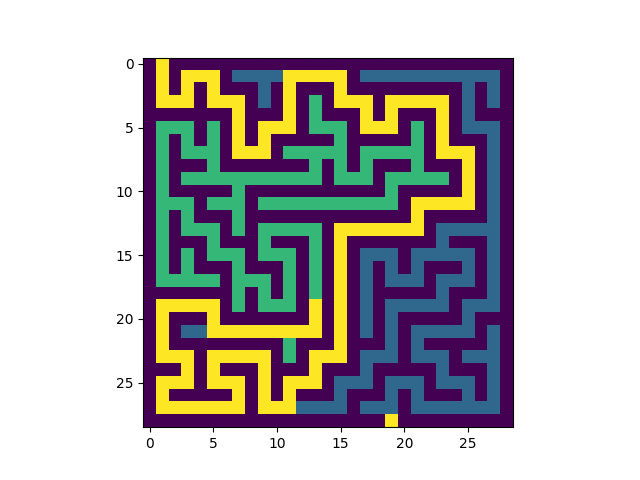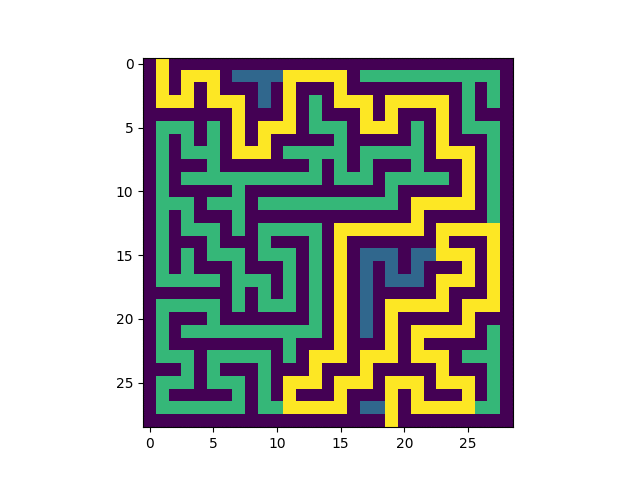 |
Q4. Ecrire une fonction ResolLab(lab:list) qui prend en argument une liste de listes représentant un labyrinthe de taille HxL et détermine le chemin entre l'entrée et la sortie en utilisant l'algorithme ci-dessus. Cette fonction modifie la variable lab par effet de bord et ne renvoie rien.
Q1. ${\tt randint(a,b)}$ donne un entier aléatoire entre ${\tt a}$ inclus et ${\tt b}$ inclus.
from random import randint
def set_initial_grid(H, L):
lab = [ [ 0 for j in range(L) ] for i in range(H) ]
xE = 2 * randint(0, L//2-1) + 1
xS = 2 * randint(0, L//2-1) + 1
lab[0][xE] = 1
lab[H-1][xS] = 1
return lab, xE, xS
Q2. On teste les "pièces" voisines: il y en a 4 saut si on se trouve le long des frontières du labyrinthe.
from random import choice
def check_voisinage(lab, pos):
H, L = len(lab), len(lab[0])
liste = []
x, y = pos
for (i, j) in [ (-2, 0), (2, 0), (0, 2), (0, -2) ]:
if 0 <= x+i < H and 0 <= y+j < L:
if lab[x+i][y+j] != 1:
liste.append((x+i,y+j))
return liste
Q3. On implémente l'algorithme proposé. La structure de pile est simplement implémenté avec une liste.
def CreeLab(H, L):
lab, xE, xS = set_initial_grid(H, L)
s = (1, xE)
lab[s[0]][s[1]] = 1
pile = [s]
while len(pile) != 0:
a_explorer = check_voisinage(lab,s)
if len(a_explorer) != 0:
new_s = choice(a_explorer)
lab[new_s[0]][new_s[1]] = 1
pos_mur = ( s[0] + new_s[0] ) // 2, ( s[1] + new_s[1] ) // 2
lab[pos_mur[0]][pos_mur[1]] = 1
s = new_s
pile.append(s)
else:
s = pile.pop()
return lab
Pour vérifier votre programme:
lab = CreeLab(59,59)
plt.imshow(lab)
<matplotlib.image.AxesImage at 0x7f279994f040>

Q4. Il faut commencer par modifier la fonction ${\tt check}\_{\tt voisinage(lab, pos):}$ pour qu'elle renvoie les "pièces" voisines qui n'ont pas encore été explorées. De plus les "pièces" voisines sont seulement celles accessibles par un "passage".
def check_voisinage_resol(lab, pos):
H, L = len(lab), len(lab[0])
liste = []
x, y = pos
for (i, j) in [ (-1, 0), (1, 0), (0, 1), (0, -1) ]:
if 0 <= x+2*i < H and 0 <= y+2*j < L:
if lab[x+i][y+j] == 1 and lab[x+2*i][y+2*j] == 1:
liste.append((x+2*i,y+2*j))
return liste
On implémente l'algorithme proposé. La structure de pile est simplement implémenté avec une liste.
def ResolLab(lab):
H, L = len(lab), len(lab[0])
for j in range(L):
if lab[0][j] == 1:
xE = j
break
for j in range(L):
if lab[H-1][j] == 1:
xS = j
break
lab[0][xE] = 3
lab[1][xE] = 3
lab[H-1][xS] = 3
s = ( 1, xE )
pile = [s]
a_explorer = check_voisinage_resol(lab, s)
while s != (H-2, xS):
if len(a_explorer) != 0:
new_s = choice(a_explorer)
lab[new_s[0]][new_s[1]] = 3
pos_mur = ( s[0] + new_s[0] ) // 2, ( s[1] + new_s[1] ) // 2
lab[pos_mur[0]][pos_mur[1]] = 3
s = new_s
pile.append(s)
else:
old_s = s
# on revient 2 fois en arrière !!
pile.pop() # on enlève le sommet car c'est une impasse
s = pile[-1] #on revient au sommet précédent celui qui est une impasse
lab[old_s[0]][old_s[1]] = 2
pos_mur = ( s[0] + old_s[0] ) // 2, ( s[1] + old_s[1] ) // 2
lab[pos_mur[0]][pos_mur[1]] = 2
a_explorer = check_voisinage_resol(lab,s)
Pour vérifier votre programme:
lab = CreeLab(59,59)
ResolLab(lab)
plt.imshow(lab)
<matplotlib.image.AxesImage at 0x7f27e462f7c0>